

This Glitter Monogrammed Pumpkin was a simple project that added some rustic glam to my front porch decor…I am just in love with it! The best part – it only took 20 minutes!
Supplies needed ((This post contains affiliate links. Click here to read my full disclosure.):
- white craft pumpkin (I got mine at Michael’s)
- Silhouette Double-Sided Adhesive & Silhouette Machine (or cut it out by hand)
- gold glitter
I purchased some Silhouette Double-Sided Adhesive a few weeks ago but wasn’t exactly sure what I’d do with it. It is essentially just 8.5×11 pieces of adhesive with a front and backing that allow you to cut it, and then peel off when you get it where you want it. Turns out, it’s pretty easy and quick to work with (depending on your design.) If you’ve never used it before, here’s a quick tutorial to create your own glitter monogrammed pumpkin! (Honestly, for a simple design like this, you don’t even really need a Silhouette – you could trace and cut it by hand!)

The first step is to load your double-sided adhesive sheet into your Silhouette using a cutting mat – yellow side down. I just used the programmed cutting settings in Silhouette Studio to cut double-sided adhesive and had no problem, but this wasn’t a very intricate design. Depending on what you’re cutting, you may want to experiment with different settings on a small piece of adhesive so you don’t waste an entire sheet.

Once it’s cut, CAREFULLY remove it from your cutting mat. My mat is fairly new and still very sticky, so I had some issues with the yellow backing sticking to the mat in some places (especially the thinner parts of the letter.) That’s not a big deal if you’re going to stick it directly to your project surface (it just leaves the adhesive exposed, which is the next step anyway), but if you set it down on something else accidentally or aren’t going to use it right away, it could be problematic.

Slowly peel off the yellow backing and then apply it to your project surface. It is not very forgiving – once it’s stuck, it’s stuck – so be careful to get the placement right the first time. If you’re applying it to a pumpkin, like me, make sure to press it completely into the grooves of the pumpkin as you go across, working from one side to the other.

Peel off the white paper to reveal the front side of the adhesive.

Now you’re ready to add the glitter! (I did this in the garage over a bin in an attempt to keep the glitter contained and out of the house!) Silhouette sells glitter specifically for use with the double-sided adhesive, and it is very fine. I just used regular craft store glitter, which is larger, but it still stuck on very well and I love how it looks.

Use a dry paint brush to remove the excess glitter. You can even brush over the adhesive to get the glitter that’s not really stuck on and make sure there’s a completely stuck layer of glitter underneath.

Ta-da! A lovely glitter monogrammed pumpkin that can be used year after year!

I just love the contrast of the rustic fall decor with the glam of the glitter. It looks so pretty when it catches the sunlight!
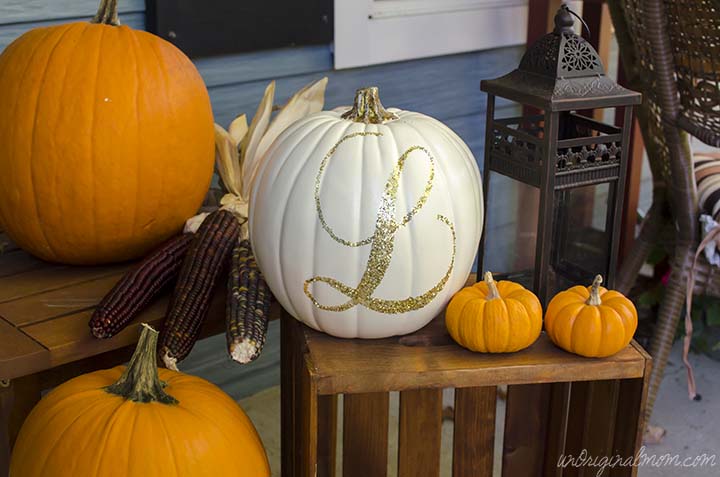
You could use this technique on a real pumpkin if you’d like – just make sure the surface is very clean and dry before you stick the adhesive on. Or you could make one with your house number, last name, a swirly flourish design…there are lots of possibilities! To be honest, for a simple design like this you don’t even really need a Silhouette – you could still buy the double sided adhesive and just trace and cut it by hand. Or you could even “paint” onto the pumpkin with some Elmer’s glue and add the glitter on top of that.

I’m really excited to try out this double-sided adhesive with glitter or flocking powder on more projects. There are definitely limitations – I don’t see how you could use transfer tape very easily, and small, intricate designs might be hard to cut out – but I’ve already got several neat ideas pinned to my Silhouette Pinterest Board that I can’t wait to try!
Update – I used double sided adhesive and on some of these wood slice ornaments and they turned out beautifully!

Psst – if you’re looking for some more inspiration in your inbox, don’t forget to sign up for new post notifications and the unOriginal Mom newsletter via email!!

Looking for some more Silhouette inspiration? This post is part of the October Silhouette Challenge, organized by Lauren at The Thinking Closet! My Silhouette Challenge buddies are all sharing projects today on their blogs, so browse through the links below for a blog-hopping good time!
Crafting with Glitter Just Got Easier by Create & Babble
Birthday Invitations Homer Simpson Style by Black & White Obsession
DIY Planner Dividers by The House on Hillbrook
3D Haunted Forest by Chicken Scratch NY
Pumpkins and Peacocks Fall Mantel by joy & gladness of heart
DIY Cheers Garland by Rain on a Tin Roof
Wedding Gift Wrapping by It Happens in a Blink
Halloween Family Rules by Tried & True
Faux Stitched Speech Bubbles by Get Silvered Craft
A Mario Bros. Backsplash by Please Excuse My Craftermath…
Halloween Spooky Eye Luminaries by A Tossed Salad Life
Addressing Invitations with a Silhouette Cameo by My Favorite Finds
Halloween Party Treat Bags by The Thinking Closet
“Create” Wooden Pallet by Lil’ Mrs. Tori
Spooky Halloween Bats Garland by TitiCrafty
Decorated Pumpkins by Tanya’s Creative Space
Cute Wedding Card by Zanaree
Learn to Tie Your Shoes by From Wine to Whine
Fussy Cutting Making You Fussy? by My Paper Craze
Cut Fabric With Your Silhouette by Cutesy Crafts
Cookie Lee Jewelry’ Gift Bags with a Purpose: Sharing Thankfulness by An Elegant Touch
Halloween Banner by Sowdering About
Thanks for stopping by!
This post contains affiliate links. Click here to read my full disclosure.)



Subscribe to unOriginal Mom via email and get instant access to my library of FREE Silhouette Studio & SVG cut files - exclusively for email subscribers. Plus there's a new file added every month!













[…] Glitter Monogrammed Pumpkin by unOriginal Mom […]
[…] Glitter Monogrammed Pumpkin by unOriginal Mom […]
[…] Glitter Monogrammed Pumpkin by unOriginal Mom […]
[…] of heart DIY Cheers Garland by Rain on a Tin Roof Wedding Gift Wrapping by It Happens in a Blink Glitter Monogrammed Pumpkin by unOriginal Mom Halloween Family Rules by Tried & True Faux Stitched Speech Bubbles by Get […]
THIS IS AMAZING! I LOVE GOLD AND GLITTER! I defiantly need to try this double sticky stuff and the glitter. And as far as you mat goes…your lucky I wish mine was still sticky. I have been meaning to “restick” mine for sometime and haven’t got around to it. I have to tape my mediums on. How crazy is that. Maybe I’ll pick up a couple of mats on my next Silhouette order. But anywho…I love this project and I’m pinning for sure! GREAT JOB!
[…] Glitter Monogrammed Pumpkin by unOriginal Mom […]
Stopping over from the Silhouette Challenge!
Great job in the cute Monogrammed Pumpkin. Glitter is seriously the best. Somehow this girl manages to contain the messs– its like a miracle. [knocks on wood]
You’ve got my PIN haha.
Much love,
Trisha D.
Thanks Trisha! I was so worried about getting glitter everywhere, haha…I did it in a bin, in the garage. I haven’t found any glitter in the house yet, so I think I was successful!
[…] of heart DIY Cheers Garland by Rain on a Tin Roof Wedding Gift Wrapping by It Happens in a Blink Glitter Monogrammed Pumpkin by unOriginal Mom Halloween Family Rules by Tried & True Faux Stitched Speech Bubbles by Get […]
I love that display !
Oh my, this is awesome! Your whole display is amazing!
Aw, thanks Glenna!! I am very happy with how it turned out!
This is such a cute idea! I love pumpkins the way they are, but this personalized touch is so cute!
Thanks Hima! I agree, I think pumpkins are lovely the way they are, but I couldn’t resist a little bit of glitz and glam ;-)
How pretty Meredith!! Simply gorgeous!! I want to try out this adhesive now!
You totally should! It was SO easy. I have a feeling there is lots of glitter in my future, haha.
That is one seriously elegant pumpkin. The glitter against the white background is lovely.
Thanks Pam! By itself, it might be a little too glitzy for me…but next to the rest of the pumpkins and things, I love the little bit of elegance it adds :-)
How lovely! The glittered monogram looks BEAUTIFUL on the pumpkin!!! Love love love it!!!
Thanks so much Maria!!
Meredith, I love it! I mean really love it! I can’t wait to make one. You’ve convinced me to get some double sided adhesive Silhouette paper!
Thanks Carrie! I am so happy with how it turned out…and it really was SUPER easy! Especially with Christmas coming up, I have a feeling I will be doing lots more projects with double sided adhesive and glitter :-)
Loving this project?! First, where did you get such a perfect white pumpkin. We were at the patch yesterday, and didn’t see one with such a perfect shape. It is real, right?
Second, I love this idea. I’ve pinned it to my Halloween board! :)
Nope Emily, it is from Michael’s! I couldn’t find anything but orange pumpkins anywhere either. But I’m glad that I’ll get to use it year after year! Thanks for pinning :-)
I do LOVE glitter, and I do LOVE monograms – super cute!
Thanks Jacquelyn! I love the personalized touch of a monogram, too :-) Thanks so much for posting the Silhouette Challenge links on your blog – so sweet of you! And thanks for stopping by!
[…] Glitter Monogrammed Pumpkin by unOriginal Mom […]
I despise glitter but seeing this project makes me want to make one of my own. I love it!
I hear ya, Randi, I was a bit apprehensive about using glitter…but I did it in the garage in a bin and kept it pretty well contained…I haven’t found any in the house yet, so I think I was successful!
Lovely, Classy Pumpkin! ;-}
Lynden
http://aneleganttouch-lynden.blogspot.com
https://www.facebook.com/Lynden.AnElegantTouch
Thanks Lynden!
Your pumpkin is so stylish and makes me wish I had a silhouette machine. I’ll have to figure something else out to achieve this project! I’d LOVE for you to share your project at Stylish Friday Finds this week!
Karen
This is GORgeous!!! I just got some of that double sided adhesive {did you know it’s on sale right now?!} and I am literally going to run outside, grab the poor unsuspecting pumpkin on the porch and DO THIS!
[…] I was really eager to try this material, especially after hearing great things about it from my friend Meredith at unOriginal Mom (check out her glitter monogrammed pumpkin project using double-sided adhesive here). […]
What a great idea to put glitter on a pumpkin! Love it!
Wow! Simple, easy and elegant. I just need one of those machines! :)
Thanks Michelle! If you wanted to, you could do this with just some Elmer’s glue and glitter pretty easily…freehand it onto a pumpkin, or even print out your pattern and trace it onto the pumpkin first! Although I’d highly recommend a Silhouette if you’re considering it…and I hear they’ve got a great promotion going on now!
Love it! I’m a chunky glitter fan, I prefer it 110% over micro glitter, so much easier to clean up too!
Aww a glittery, monogrammed pumpkin!! It’s absolutely adorable! I definitely need to go get myself some double adhesive vinyl. Great Job!
Okay, you are totally responsible for empowering me to tackle my DIY Photo Booth Props that I shared in my post Tuesday…so thank you for singing the praises of Double-Sided Adhesive. I have now seen the light myself! It’s amazing. And I actually have a pumpkin project for later this week, and I think I might need to use some double-sided adhesive in the process. Your monogrammed L just looks so fantabulous! (And you know I’m partial to the letter L.) Gorgeous!
Aw, shucks! So glad I could be the nudge you needed to give it a try :-) I still can’t believe how easy it was to use…I foresee a lot of glitter in my holiday projects!
This is so pretty! A pumpkin has never looked more elegant!
FABULOUS! I’m getting ready to make a Cinderella pumpkin, so I stopped by from Someday Craft to check out how you did yours. Thanks for the great tutorial!
I love this so much! Im a white pumpkin kind of gal. And a glitter kind of gal. Im in love with your pumpkin! One of these days ill have to buy one of those silhouettes, theyre just so dang expensive but i see these cool projects, ugh!
[…] UnOriginal Mom: Glitter Monogramed Pumpkin […]
That is one perty pumpkin! I love the gold on the white! so pretty!
I pretty much hate pumpkin carving- the patience, the goo, the mess! This is a pumpkin decoration I can behind- glitter and glue! Sold.
This is truly beautiful! Love this brilliant pumpkin idea. I’d love for you to link this up to my weekly link party! Consider yourself invited! :) http://thelifeofjenniferdawn.blogspot.com/2013/10/a-little-bird-told-me-link-party-63.html
Wow I would have never thought to add a sticker. So smart!
Love this pumpkin! The sticker is very clever. Thanks for sharing.
Hello! Visiting from the Craftionary linky party! I have to win a silhouette ;) Lovely project!
I love this! It would be a great addition to a fall party! If you get a chance you can enter it into the Perfectly pumpkin contest
http://piwiprincess.blogspot.com/2013/10/PerfectlyPumpkincontest2013.html
This is SO pretty!! I love the contrast between the sparkly monogrammed pumpkin and the other more typical fall decor!
I’d love to invite you to share this (and anything else pumpkin you’d like!) at the Perfectly Pumpkin Contest–you can see it at http://preschoolpowolpackets.blogspot.com/2013/10/2013-perfectly-pumpkin-contest.html I hope we see you there!
Beautiful! I love how simple yet elegant it is!
[…] Today I have a real treat for you, friends! A project that combines three of my very favorite things…pumpkins, Cammie {my beloved Silhouette Cameo}, and… GLITTER! This week, I promised to share with you a variety of ways to use the various specialty media that’s on sale right now at Silhouette. But unlike the other projects I’ve showed, this project was not my idea! Instead, this piece of festive fabulousness is the creative brainstorm of Meredith over at Unoriginal Mom. […]
This is gorgeous! Love it!
Love this so much! Mmm, gold glitter love!
[…] Dipped Flower Vase Pumpkin from Homey Oh My! Fall Front Porch from Moving Forward Redesign. Glitter Monogrammed Pumpkin from Unoriginal Mom. Rustic Pumpkin Sign from Lake Girl Paints Beautiful Fall Home Tour […]
[…] OaksGold Dipped Flower Vase Pumpkin from Homey Oh My!Fall Front Porch from Moving Forward Redesign.Glitter Monogrammed Pumpkin from Unoriginal Mom.Rustic Pumpkin Sign from Lake Girl PaintsBeautiful Fall Home Tour from Rain on […]
[…] OaksGold Dipped Flower Vase Pumpkin from Homey Oh My!Fall Front Porch from Moving Forward Redesign.Glitter Monogrammed Pumpkin from Unoriginal Mom.Rustic Pumpkin Sign from Lake Girl PaintsBeautiful Fall Home Tour from Rain on […]
Stunning!!! I’m convinced that I need to get a Silhouette.
Thanks, Amy! I can’t say enough great things about my Silhouette…it was definitely the best crafting purchase I’ve ever made! If you get one, you won’t regret it :-)
I lurve these! How glam! They caught my eye right away (probably the glitter since I may have an addiction to it, haha). I want to let you know that I’ve featured your gorgeous pumpkins on my Finding Friday: My Favorite Finds post yesterday!
Be sure to swing by and check it out! http://itsalwaysruetten.blogspot.com/2013/10/finding-friday-my-favorite-finds_18.html
Stopping by from the pumpkin linky. Your glittered monogram caught my eye. Now, I wish I had a Silhouette machine!
This was very creative and beautiful.
Hi Dana, thanks for visiting and following! I have to tell you, I didn’t know how much I needed a Silhouette until I got one…the crafting possibilities are endless! There are always lots of Silhouette giveaways going on in blog-world – be sure to enter, you might just win one!
And, I meant to add that you have a new follower…
Your pumpkin is absolutely gorgeous! Thank you for sharing!
Thanks Katie! So glad you like it!
I couldn’t let this week go by without featuring these adorable pumpkins @ Tell Me Tuesday! Thanks for linking up Meredith!
You are just too sweet! Thanks for the feature, Tori!!
[…] – The Thinking Closet// Coffee Filter Wreath – Alisha Grate // Monogrammed Pumpkin – Unoriginal Mom Remember to check out Ashley’s features here! Go here to grab party and feature […]
[…] Glitter Monogrammed Pumpkin via Unoriginal Mom (Meet the preppy […]
So so so cute Meredith! Love this! You are so creative. I love the glitter with the white pumpkin, so need to go out and get me a white pumpkin! :) Thanks for sharing at Show Stopper Saturday!
Krista @ Joyful Healthy Eats
Thanks, Krista!! I love the white pumpkin, too…I was disappointed I couldn’t find a real white pumpkin anywhere, so I had to settle for a fake one. Oh well!
[…] from & directions on Unoriginal Mom […]
This is a great Halloween project! Thanks for sharing it at The Pin Junkie Link Party. This project was featured in a HUGE Halloween roundup. Hope you can stop by to grab a button and let everyone know that you were featured on The Pin Junkie. http://www.thepinjunkie.com/2013/10/halloween-roundup-31-halloween-projects.html
every pumpkin should have a little glitter! so fab! featuring you tonight.
Hi Meredith, What a gorgeous project. I am “pinning” so I will remember to give it a try. Thanks for the great tutorial.
Warmly, Michelle
[…] Glittered Monogram Pumpkin – shared by Unoriginal Mom […]
Hi there!
I just wanted to pop over and let you know that I’ve shared this post in an inspiration board for a “Give {glittery} Thanks” post my blog.
Here is the direct link to the post if you want to check it out:
http://uniquepasticheevents.com/2013/10/30/give-glittery-thanks/
Thanks for sharing this post! I may have never found what I was looking for :)
[…] Glitter Monogrammed Pumpkin by unOriginal Mom […]
[…] used double-sided adhesive to cut out the lettering, then added glitter for a little glam! (Click HERE for a tutorial on using double-sided adhesive and […]
[…] Glitter Monogrammed Pumpkin from UnOriginal Mom- This tutorial demonstrates how to easily use Double Sided Adhesive […]
[…] of heart DIY Cheers Garland by Rain on a Tin Roof Wedding Gift Wrapping by It Happens in a Blink Glitter Monogrammed Pumpkin by unOriginal Mom Halloween Family Rules by Tried & True Faux Stitched Speech Bubbles by Get […]
[…] Glitter Monogrammed Pumpkin by unOriginal Mom […]
[…] Glitter Monogrammed Pumpkin by unOriginal Mom […]
[…] My kids like to carve pumpkins but I just like to decorate them, I found this cute idea at: unoriginalmom […]
[…] Glitter Monogrammed Pumpkin by UnOriginal Mom […]
Oh my goodness! GORG. US!
So pretty! It’s amazing what you can do with a silhouette!
What a neat idea!!! I love anything gold so this is perfect for me! Pinned :)
This is BEAUTIFUL! well done
Sarah @ EDEA Smith
http://www.edea-smith.co.uk
That is absolutely gorgeous!
If you don’t mind me asking, where did you get the large script “L” from?? I’m new to the Silhouette world and just ordered the double sided adhesive so I can tackle this as my first project!!
This is so pretty! Great idea! Stopping by from the Creativity Unleashed party – now following you! Have a great weekend!
Easy peasy and so darn stick’n cute – love this idea!
Oh how I love decorating pumpkins for fall. This is a darling idea! Thanks for some inspiration!!
This is ingenious! I love it :)
[…] Glitter Monongrammed Pumpkin by Unoriginal Mom […]
[…] Glitter Monongrammed Pumpkin by Unoriginal Mom […]
This is so pretty, Meredith! Thank you so much for sharing at Project Inspire{d} ~ your lovely pumpkin is part of this week’s What a Great Idea round. Pinning :)
[…] 1. Glittered Monogram Pumpkin by Unoriginal Mom […]
[…] 1. Glittered Monogram Pumpkin by Unoriginal Mom […]
[…] 1. Glittered Monogram Pumpkin by Unoriginal Mom […]
[…] 1. Glittered Monogram Pumpkin by Unoriginal Mom […]
Beautiful! Featured you tonight on Do Tell Tuesday–thanks for sharing!
[…] Glitter Monogrammed Pumpkin […]
[…] Glitter Monogrammed Pumpkin || Unoriginal Mom || I love those white pumpkins and how classy this one looks with the gold monogram! […]
Such a fabulous idea! Monograms, glitter, and pumpkins…3 of my favorites! I can’t wait to try this one!! :)
Hi Meredith! I just wanted to let you know that I LOVE your Glitter Monogrammed Pumpkin, and I’m featuring you as one of my Rockstars this week from Creativity Unleashed!
As a Rockstar you’re in the running for this week’s MEGA Rockstar! Grab your friends and come vote at http://www.theboldabode.com/2014/09/letters-rockstars-creativity-unleashed-week-37.html
The MEGA Rockstar gets loads of love including:
1. Shout outs on all my social media houses.
2. A bucket full of Pins to my biggest group boards
3. A big sidebar ad proclaiming them the MEGA Rockstar of the week
Congratulations and Good Luck!!!
[…] Monogramed Pumpkin would look great on your front porch […]
What an amazing and creative idea! So simple too :)
[…] And these Glitter Monogrammed Pumpkins by UnOriginal Mom […]
[…] Make a glittered monogrammed pumpkin […]
[…] Glitter Monogrammed Pumpkin […]
[…] 11. Glitter Monogram from unOriginal Mom […]
This is just beautiful! I have created a new blog, and linked to your craft there: http://autumnfunforthewholefamily.blogspot.com/2014/09/glitter-monogrammed-pumpkin_23.html
[…] Glittered Monogrammed Pumpkin via UnOriginalmom […]
[…] Are you past the pumpkin carving? Trade the face for a sparkly monogram instead and you’re front porch will be the most glamorous on the block. (via Unoriginal Mom) […]
[…] Are you past the pumpkin carving? Trade the face for a sparkly monogram instead and you’re front porch will be the most glamorous on the block. (via Unoriginal Mom) […]
[…] 1. Glittered Monogram Pumpkin by Unoriginal Mom […]
[…] Glitter Monogram Pumpkin by Unoriginal Mom. […]
[…] Glitter Monogram Pumpkin by Unoriginal Mom. […]
[…] your idea of crafting, try using a little adhesive and glitter to make a monogramed pumpkin. unOriginal Mom uses an electronic template for a crisp design, but good ol’ fashioned Mod Podge can also do […]
[…] 3} Monogram :: Use paint, sequins, or a stick on letter […]
[…] 04. Glitter Monogrammed Pumpkin Who doesn’t love a good monogrammed pumpkin? Add glitter to it and you have yourself one totally adorable pumpkin! Unoriginal Mom […]
[…] Un original mom nos proponen otra calabaza blanca con letra de […]
[…] Un original mom nos proponen otra calabaza blanca con letra de […]
[…] Glitter Monogrammed Pumpkin […]
[…] 1I2I3I4 […]
[…] including this beautiful pumpkin vase. Meredith the unOriginal Mom, gets pretty original in her tutorial for creating a glitter monogrammed pumpkin and the best thing about all of these – they are […]
What size is your pumpkin? I love this idea. Want to try it myself
Hm, without venturing outside on this chilly fall evening to measure it, I’d say it’s between 10-12″ tall? I bought it at Michael’s last year, but have seen similar ones there this year!
Love the idea. Can this double sided product be used on fabric or is there a glitter product that can be adhered to fabric. Also, how large is the initial and where can I get it. Thanks.
Hi Marianne, I’d recommend using glitter heat transfer vinyl on fabric for a similar effect! You’d need a Silhouette machine (as described in my tutorial) and can create your own initials with fonts you have on your computer using the Silhouette Studio software. If you don’t have a Silhouette, perhaps some kind of glitter fabric, iron-on interfacing, and a monogram stencil?
[…] Unoriginal Mom: Glitter Monogrammed Pumpkin […]
[…] After sign: Dreamy Wedding Ideas / Hot Apple Cider Stand: Ruffled Blog / monogramed pumpkin: Unoriginal Mom / yellow flowers: Flickr / Me & You […]
I LOVE THIS! What font did you use? I absolutely love the swirly look.
[…] 7. Glitter Monogram […]
[…] love the glittered monogram pumpkin from Un Original Mom. Visit her blog for the […]
[…] 9. Glitter White Pumpkin […]
[…] via Unoriginal Mom […]
[…] Glitter Monogrammed Pumpkin // A little rustic, a whole lot glam! These glitter pumpkins feature the letter of your choosing thanks to adhesive sheets and glitter. […]
[…] 2. Monogram Pumpkin – Unoriginal Mom […]
[…] monograms? Then you’ll love this Glitter Monogram Pumpkin from Unoriginal Mom! Faux pumpkins and gold glitter will create a gorgeous Halloween decoration […]
[…] Fall DIY: Glitter Monogrammed Pumpkin. Just think how cool this would look on your Thanksgiving […]
[…] Glitter Monogrammed Pumpkin by Unoriginal […]
[…] Glitter Monogrammed Pumpkin from UnOriginal Mom […]
[…] unoriginalmom.com […]
[…] 9. Glitter White Pumpkin […]
[…] Glitter monogram pumpkin This one looks so simple and elegant and I think this looks very nice in an hallway together with some candles. […]
[…] Image + Tutorial: UnOriginalMom.com […]
[…] about some gold dipped place cards? 7. Woah!!! Turn a pumpkin into a wine ice bucket. 8. Well a monogram, of course. 9. Can you believe these are thumbtacks?? 10. Write some witty words using […]
[…] Unoriginal Mom: Glitter Monogrammed Pumpkin […]
[…] Witch Hat Cupcakes. // 2. Spiderweb eye makeup. // 3. 50 Easy fall decorating projects. // 4. Glitter monogrammed pumpkin. // 5. Halloween door decorations. // 6. 30 quick and easy Halloween treats. // 7. Halloween mantel […]
[…] source […]
[…] source […]
[…] […]
[…] Add a monogram to a pumpkin for a fun and classy […]
[…] unoriginalmom.com […]
[…] via Unoriginal Mom […]
I am in love with how easy this looks! I am definitely going to try this one out for Fall! Thank you so much for sharing!
[…] Monogrammed Glitter Pumpkin by Unoriginal Mom […]
[…] Glitter Monogram from Unoriginal Mom […]
Love how simple this project is! Giving it a shout out on Twitter today, @Estimake :)
[…] Glitter Monogrammed Pumpkin – Unoriginal Mom […]
[…] (I love monograms) Here is a white pumpkin with a glitter monogram for your front porch. The Unoriginal Mom shows you how easy to do this without messy glue!! Another idea I must […]
Amazing! The first attempt did not work =)
[…] with jewel-tone flowers and plants with them. Finally, you can glitz up your front door by adding a glitter monogram onto a white-painted […]
[…] Glitter Monogrammed Pumpkin – Unoriginal mom […]
[…] http://www.unoriginalmom.com/glitter-monogrammed-pumpkin/ […]
[…] Glitter Monogrammed Pumpkin – This is a great take on decorating your front porch for autumn. Paint a real or faux pumpkin white, then add a wealth of glitter in a monogram to add instant elegance to your porch. Surround it with smaller orange pumpkins for contrast. […]
[…] Glitter Monogrammed Pumpkin from Unoriginal […]
[…] Glitter and a Monogram– I think I’m in love. […]
[…] Greet your guests thru Thanksgiving with this glittered Initial Pumpkin from UnOriginalmom.com […]
[…] http://www.unoriginalmom.com/glitter-monogrammed-pumpkin/ […]
[…] for all. I love decorating with pumpkins, especially when they are glittery and gold. Meredith at unOriginal Mom monogrammed her pumpkin in the most beautiful way. Click the link to find out how. Or check out my […]
[…] Pumpkin Power […]
[…] Monogrammed Pumpkins […]
[…] Glittered Monogram Pumpkin | UnOriginal Mom […]
[…] Glitter Monogrammed Pumpkin // by UnOriginal Mom […]
[…] ]Copper Striped Pumpkins | Homey Oh My!Stack-O-Lantern | Brit + CoGlitter Monogrammed Pumpkin | UNORIGINAL MOMGlitter Dipped Pumpkins | The Farmer’s […]
[…] Source […]
[…] Glitter Monogrammed Pumpkin @ Unoriginal Mom […]
[…] Wow – Monogrammed Pumpkins from UnOriginal Mum […]
[…] […]
[…] Glitter Monogrammed Pumpkin – This is a great take on decorating your front porch for autumn. Paint a real or faux pumpkin white, then add a wealth of glitter in a monogram to add instant elegance to your porch. Surround it with smaller orange pumpkins for contrast. […]
[…] with jewel-tone flowers and plants with them. Finally, you can glitz up your front door by adding a glitter monogram onto a white-painted […]
[…] 1. Glittered Monogram Pumpkin by Unoriginal Mom […]
This looks relatively simple and doable! My head is spinning with ideas now! Thanks!
I love the idea, it’s quite simple and doable. I might try it sometime when I’m free.
[…] Glitter & White Monogrammed Pumpkin […]
Wow, these are really cool ideas for Halloween. Thanks a ton.
[…] Glitter Monogram Pumpkin […]
[…] from Unoriginal Mom […]
[…] Source […]
[…] Gold Leaves from Michelle Edgemont | Glitter Monogrammed Pumpkin from Unoriginal Mom | Glitter Pumpkin Candle Holders from Twig and […]
[…] Glitter Monogram Pumpkin […]
[…] Glitter a letter. […]
[…] forget pumpkins, but we love the idea of branching out with the pumpkin creativity. These white pumpkins with glitter letters (yes, glitter!) are just too fun to pass up. Use the monogram of your last name, or let each kid […]
[…] add some pumpkins to that front porch. And if there’s one thing better than pumpkins, it’s pumpkins and glitter. The white paint gives the glitter an extra special pop, and the personalized monogram adds the […]
[…] Add some rustic glam to your front porch this fall! Tutorial via: Unoriginal Mom. […]
[…] : 1. "Emily Benziger" / 2. "HOM homeyohmy" / 3. "Un Original Mom" / 4. […]
[…] Glitter Monogrammed Pumpkin – This is a great take on decorating your front porch for autumn. Paint a real or faux pumpkin white, then add a wealth of glitter in a monogram to add instant elegance to your porch. Surround it with smaller orange pumpkins for contrast. […]
[…] Glitter Monogrammed Pumpkin – This is a great take on decorating your front porch for autumn. Paint a real or faux pumpkin white, then add a wealth of glitter in a monogram to add instant elegance to your porch. Surround it with smaller orange pumpkins for contrast. […]
Oh My Gosh, This is cool idea for Halloween. I love the idea, it’s quite simple but quirky. Thanks for sharing!
[…] Source/Tutorial: unoriginalmom […]
[…] Glitter Monogrammed Pumpkins by Unoriginal Mom […]
How creative you are. This monogrammed pumpkin is stunning. I will make this and it will look great to take this pumpkin in my living room
thanks for your post
[…] Glitter Monogrammed Pumpkin from Unoriginal […]
[…] {View Tutorial} […]
[…] This Glitter Monogrammed Pumpkin will add some rustic glam to your front porch. (via Unoriginal Mom) […]
[…] For a more personalized look, there’s this Glitter Monogrammed Pumpkin. Check out the tutorial here from Unoriginal Mom. […]
[…] Source: Unoriginal Mom […]
[…] It! That’s what the unOriginalMom did. And it looks […]
[…] a beautiful Glitter Monogramed Pumpkin to welcome guests to your home all season long. Meredith from Unoriginal Mom created this gorgeous […]
[…] at the Unoriginal Mom is here to keep us glam this fall with this lovely glitter monogramed pumpkin. She uses a simple […]
[…] a beautiful Glitter Monogramed Pumpkin to welcome guests to your home all season long. Meredith from Unoriginal Mom created this gorgeous […]
[…] Found at Un Original Mom […]
[…] unoriginalmom […]
[…] Monogramed Pumpkin would look great on your front porch from Unoriginal Mom. […]
[…] Greet your guests thru Thanksgiving with this glittered Initial Pumpkin from UnOriginalmom.com […]
[…] 6. Glitter Monogrammed Pumpkin – Unoriginal Mom […]
[…] Glitter Monogram Pumpkin from Unoriginal Mom […]
[…] Photo Credit: Unoriginal Mom […]
[…] Source: Unoriginal Mom […]
You KNOW you ahd me at “glitter” – What a smarty pants way to monogram. I’m so low tech when it comes to crafting. I love that you could just cut the letter out! And, that these pumpkins will last and last :)
[…] Flower Vase Pumpkin from Homey Oh My! Fall Front Porch from Moving Forward Redesign. Glitter Monogrammed Pumpkin from Unoriginal Mom. Rustic Pumpkin Sign from Lake Girl Paints Beautiful Fall Home Tour […]
[…] Add a little glam to your front porch – in 20 minutes with this idea via Unoriginal Mom […]
Love the glitter details
[…] Glitter Monogrammed Pumpkin – unOriginal Mom […]
[…] Photo from Unoriginal Mom […]
[…] paint on simple letter stencils for longer-lasting words, or glitter monograms if you’re more glam. Express a simple greeting like “Welcome” or “Happy Fall” (or […]
[…] from Unoriginal Mom […]
[…] Inspiration + Photo Credit: Unoriginal Mom […]
These Christmas wood slice ornaments are indeed beautiful!
I’ll “steal” this idea and add it to my Christmas tree!
Thanks for sharing this beautiful article!
[…] actually got the idea for this project from Unoriginal Mom and now I want to add glitter monograms to everything. Here’s what I used to make my glitter […]
[…] Make designs with glitter glue, or put Modge Podge on your pumpkin and shower it with glitter! Get creative with […]
You can also mix some glue with about double the amount of glitter to make a paste to paint your goodies with. You can add more layers if you want to. Glitter won’t go anywhere without the sealer! I like this method because you can feel the texture of the glitter when you hold it after drying.
What a great idea to put glitter on a pumpkin! Love it!
This looks so cool yet easy to make. Love this!
[…] Add some rustic glam to your porch with glitter monogrammed white pumpkin. Learn how to make it from unoriginalmom […]
[…] Source […]
[…] Add a monogram to a pumpkin for a enjoyable and fashionable […]
[…] at Unoriginal Mom used a Silhouette Machine to make this pretty monogram pumpkin, but you can also trace the monogram by hand so you don’t need a special machine to make this […]
[…] Add a monogram to a pumpkin for a enjoyable and fashionable […]
What size is your pumpkin? I love this idea. Want to try it myself
It’s just a normal size faux pumpkin from Michael’s, probably about 12″ wide I’d guess?
Love this Glitter Monogrammed Pumpkin, this craft seems so amazing , thanks for sharing with us.
[…] 13. Glitter Monogrammed Pumpkin […]
[…] Add a monogram to a pumpkin for a enjoyable and stylish […]
[…] via Unoriginal Mom […]
This is such a creative and fun way to decorate your pumpkin! I’m definitely going to try it this year!
[…] Courtesy of: Left: Unoriginal Mom Right: Brenda’s Wedding […]
[…] via Unoriginal Mom […]
Wow, this Glitter Monogrammed Pumpkin DIY looks amazing and so simple to make! I love how you combined rustic charm with a touch of glam. The step-by-step tutorial is really helpful, especially for someone like me who’s new to using double-sided adhesive. Thanks for the inspiration and detailed instructions! Can’t wait to try this out on my porch decor!
This glitter monogrammed pumpkin is absolutely stunning! I love how you’ve combined rustic charm with a touch of glam—it’s such a unique twist on traditional fall decor. The step-by-step tutorial made the process look so approachable, even for those of us without a Silhouette machine (yay for the hand-cutting option!). I especially appreciate your tips about working with the adhesive and glitter—super helpful to know about the sticky mat issue in advance. Definitely adding this to my DIY fall decor list. Thanks for the inspiration!